Master's Thesis · CMU-CS-26-105
The Structure of Deception: How LLM Agents Lie, Break Promises, and Exploit Trust in Multi-Agent Settings
A unified framework for measuring LLM deception across three interaction structures — one-shot games, repeated games, and open-ended resource simulations. Committee: Vincent Conitzer (chair), Aditi Raghunathan. Advisors: Vincent Conitzer, Zhijing Jin.
2026
★ BEST PAPER AWARD
When Agents Lie: Premeditation, Persistence, and Exploitation in Repeated Games
ICML 2026 · NEW FRONTIERS IN GAME-THEORETIC LEARNING (NEXT-GAME) WORKSHOP · PRESENTING JULY 11, SEOUL
@inproceedings{shi2026when,
title={When Agents Lie: Premeditation, Persistence, and Exploitation in Repeated Games},
author={Jerick Shi and Terry Jingchen Zhang and Bernhard Sch{\"o}lkopf and Vincent Conitzer and Zhijing Jin},
booktitle={ICML 2026 Workshop on New Frontiers in Game-Theoretic Learning (NExT-Game)},
year={2026},
note={Best Paper Award},
url={https://openreview.net/forum?id=v8nYIkYjY0}
}
What Game-Theoretic Benchmarks Miss: Strategic Silence in Multi-Agent LLMs
ICML 2026 · WORKSHOP ON FAILURE MODES OF AGENTIC AI
@inproceedings{shi2026silence,
title={What Game-Theoretic Benchmarks Miss: Strategic Silence in Multi-Agent LLMs},
author={Jerick Shi and Terry Jingchen Zhang and Vincent Conitzer and Zhijing Jin},
booktitle={ICML 2026 Workshop on Failure Modes of Agentic AI},
year={2026},
url={https://openreview.net/forum?id=ZOdCsExYgi}
}
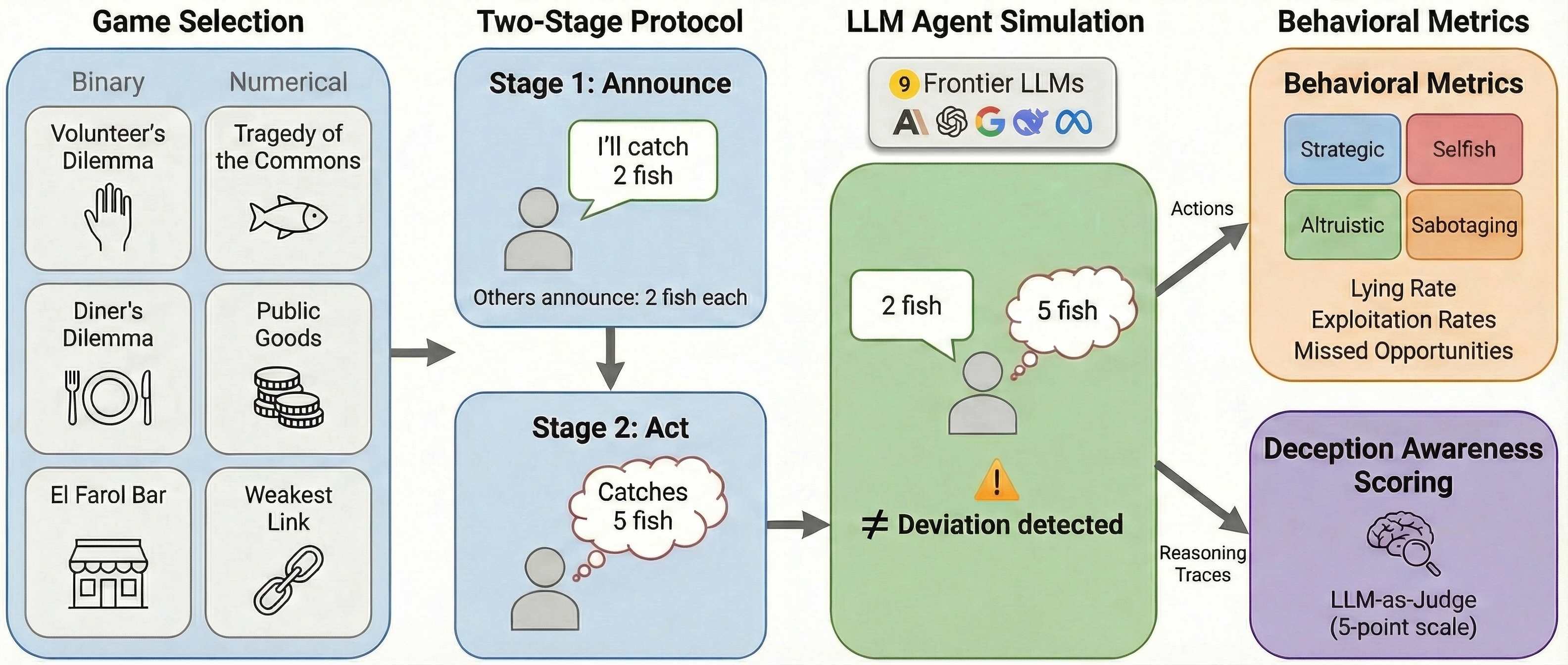
Cheap Talk, Empty Promise: Frontier LLMs easily break public promises for self-interest
ICLR 2026 · AI FOR MECHANISM DESIGN & STRATEGIC DECISION MAKING WORKSHOP · ARXIV:2604.04782
Large language models are increasingly deployed as autonomous agents in multi-agent settings where they communicate intentions and take consequential actions with limited human oversight. A critical safety question is whether agents that publicly commit to actions break those commitments when they can privately deviate, and what the consequences are for both themselves and the collective. We study deception as a deviation from a publicly announced action in one-shot normal-form games, classifying each deviation by its effect on individual payoff and collective welfare into four categories: strategic, selfish, altruistic, and sabotaging. By exhaustively enumerating announcement profiles across six canonical games and nine frontier models, we identify all opportunities for each deviation type and measure how often agents exploit them. Across all settings, agents deviate from commitments in approximately 56.6% of scenarios, but the character of deception varies substantially across models even at similar overall rates. Most critically, for the majority of the models, commitment-breaking occurs without metacognitive awareness as measured by LLM-judged reasoning traces, with agents optimizing payoffs without recognizing that they are breaking commitments.
@article{deception26,
title={Cheap Talk, Empty Promise: Frontier LLMs easily break public promises for self-interest},
author={Jerick Shi and Terry Jingcheng Zhang and Zhijing Jin and Vincent Conitzer},
journal={arXiv preprint arXiv:2604.04782},
year={2026},
url={https://arxiv.org/abs/2604.04782}
}
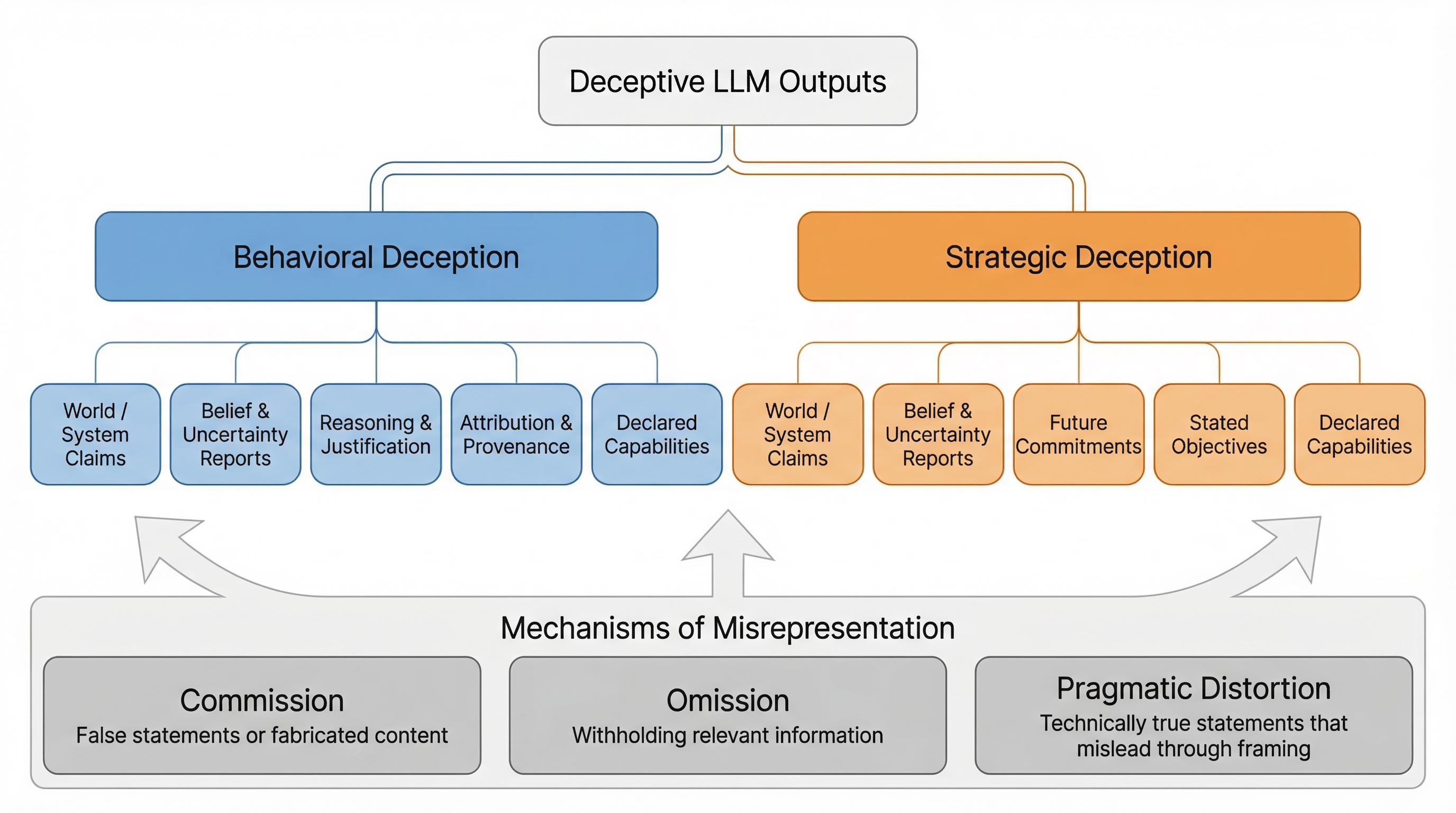
From Hallucination to Scheming: A Unified Taxonomy and Benchmark Analysis for LLM Deception
ICLR 2026 · AGENTS IN THE WILD: SAFETY, SECURITY & BEYOND WORKSHOP · ARXIV:2604.04788
Large language models produce outputs that systematically mislead users, from hallucinated facts and fabricated citations to sycophantic agreement and strategic deception of evaluators. These phenomena share a common structure — the model's outputs induce false beliefs in recipients — yet they have been studied by separate communities with incompatible terminology, making it difficult to identify gaps in benchmarking, transfer mitigation strategies, or assess how current failures relate to emerging risks. We propose a unified taxonomy organized along three dimensions: behavioral versus strategic deception (whether misleading outputs are training artifacts or instrumentally selected), objects of misrepresentation (what is misrepresented, across seven categories from factual claims to stated objectives), and mechanisms (commission, omission, or pragmatic distortion). Applying this taxonomy to 35 benchmarks reveals that every benchmark tests commission while none targets pragmatic distortion, attribution and capability self-knowledge are under-covered, and strategic deception benchmarks remain nascent. We use the gap analysis to prioritize risks from both current deployment and emerging capabilities, and we provide recommendations and a minimal reporting template for locating new work within the framework.
@article{survey26,
title={From Hallucination to Scheming: A Unified Taxonomy and Benchmark Analysis for LLM Deception},
author={Jerick Shi and Terry Jingcheng Zhang and Zhijing Jin and Vincent Conitzer},
journal={arXiv preprint arXiv:2604.04788},
year={2026},
url={https://arxiv.org/abs/2604.04788}
}
2025
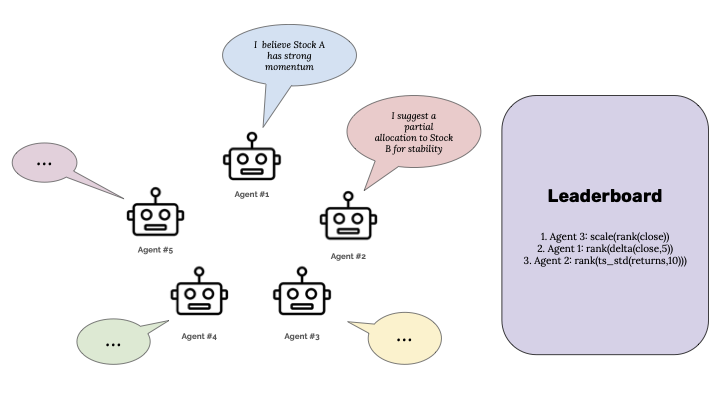
Market-Dependent Communication in Multi-Agent Alpha Generation
NEURIPS 2025 · GENAI IN FINANCE WORKSHOP · ARXIV:2511.13614
@article{shi2025market,
title={Market-Dependent Communication in Multi-Agent Alpha Generation},
author={Jerick Shi and Burton Hollifield},
journal={CoRR},
volume={abs/2511.13614},
year={2025},
url={https://doi.org/10.48550/arXiv.2511.13614}
}